Fixes#14551
### What problem does this PR solve?
The Moodle connector did not let the sync runner clean up indexed
documents that were deleted from the source. Other connectors such as
dropbox, seafile, webdav, and rss already do this through a slim
snapshot pass. This PR adds the same support for Moodle.
When `sync_deleted_files` is on, the runner now asks the Moodle
connector for a lightweight list of every module id that could be
indexed. The runner then compares this list with the index and removes
any indexed document whose id is not in the list.
The slim pass does not download files. It only goes through courses and
modules and yields ids. The id format matches the ids that the loader
produces, so the match is exact.
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### Notes
- `MoodleConnector` now also implements `SlimConnectorWithPermSync`.
- New `retrieve_all_slim_docs_perm_sync` yields slim docs with the same
ids the loader uses (`moodle_resource_<id>`, `moodle_forum_<id>`,
`moodle_page_<id>`, `moodle_book_<id>`, `moodle_assign_<id>`,
`moodle_quiz_<id>`).
- The `Moodle` sync class now returns `(document_generator, file_list)`
so the runner can do the cleanup. If the slim snapshot fails,
`file_list` is set back to `None` and the run continues without cleanup.
- The web data source map exposes `syncDeletedFiles` for Moodle so the
option shows up in the UI.
### How was this tested?
- `ruff check` passes on the changed Python files.
- Manual review of the produced slim ids against the ids the loader
builds in `_process_resource`, `_process_forum`, `_process_page`,
`_process_book`, and `_process_activity`.
- Behavior parity with the merged dropbox (#14476), seafile (#14499),
webdav (#14491), and rss (#14493) PRs.
### What problem does this PR solve?
Since secret key get and set logic is updated, the go server also need
to update.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
---------
Signed-off-by: Jin Hai <haijin.chn@gmail.com>
Fixes#14159
## Problem
The `put()`, `get()`, `rm()`, and `obj_exist()` methods in both
`azure_spn_conn.py` and `azure_sas_conn.py` ignore the `bucket`
parameter entirely, storing all files flat using only the filename. This
causes files from different datasets to overwrite each other when they
share the same filename.
By contrast, the MinIO and S3 implementations correctly use the bucket
(typically the knowledge base ID) as a path prefix, creating logical
folder isolation like `{kb_id}/{filename}`.
## Solution
Prepend the `bucket` parameter as a path prefix to all file operations
in both Azure storage implementations:
- `azure_spn_conn.py`: `create_file`, `delete_file`, `get_file_client`
now use `f"{bucket}/{fnm}"`
- `azure_sas_conn.py`: `upload_blob`, `delete_blob`, `download_blob`,
`get_blob_client` now use `f"{bucket}/{fnm}"`
This matches the behavior of all other storage backends (MinIO, S3) and
prevents filename collisions across knowledge bases.
## Testing
- Verified the fix aligns with how MinIO/S3 connectors handle the bucket
parameter
- The `health()` method is left unchanged as it uses a fixed test path
for connectivity checks only
Co-authored-by: octo-patch <octo-patch@github.com>
Co-authored-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
preserve doc generator download metadata
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
### What problem does this PR solve?
Follow on PR: https://github.com/infiniflow/ragflow/pull/14602
to fix: team member cannot edit agent.
new behavior: beside delete, everything is allowed for team member.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
### What problem does this PR solve?
1. **Implement `Nvidia` Provider:** Fully support NVIDIA NIM APIs with
robust parameter handling (including the `thinking` parameter) and safe
URL merging in `NewInstance`.
2. **Fix Misleading CLI Errors:** Corrected a bug in `common_command.go`
where failed chat requests inaccurately reported `failed to list
instance models`.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
- [x] New Feature (non-breaking change which adds functionality)
### What problem does this PR solve?
Feat: enable sync deleted files for RDBMS & fix remove last file issue
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
- [x] New Feature (non-breaking change which adds functionality)
### What problem does this PR solve?
Add a Go driver for OpenAI (GPT models).
The config file conf/models/openai.json has been in the repo for a while
with the full GPT-5 model list, but
internal/entity/models/factory.go had no case for "openai". So any
tenant that configured OpenAI as a model provider in the Go layer fell
through to the default branch and got the dummy driver. Chat, list
models, and check connection all returned dummy responses instead of
reaching the API.
OpenAI is the most commonly requested provider and the JSON config
already ships with the repo, so this gap is high impact even though the
JSON has been there for some time.
### What this PR includes
- New file internal/entity/models/openai.go with an OpenAIModel that
implements the ModelDriver interface.
- factory.go: route the "openai" provider name to NewOpenAIModel.
- conf/models/openai.json: add "models": "models" under url_suffix so
ListModels can hit /v1/models with no hardcoded fallback.
### How the driver works
- OpenAI exposes the canonical OpenAI-compatible API at
https://api.openai.com/v1.
- ChatWithMessages and ChatStreamlyWithSender post to /chat/completions
in the same shape the moonshot, vllm, and xai drivers use.
- ListModels and CheckConnection call /models to list available ids and
confirm the API key works.
- reasoning_content is passed through for the o-series and other
reasoning models, in both the non-stream and stream paths.
- Encode (embeddings) is left as "not implemented" for now, the same way
the other recent provider drivers do it. Rerank and Balance are not part
of OpenAI's public API surface in this layer and return a clear "not
implemented" or "no such method" error.
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### How was this tested?
- go build ./internal/entity/models/... in a clean go 1.25 image (the
go.mod minimum) returns exit 0 with no errors.
- Method set of OpenAIModel matches the ModelDriver interface:
NewInstance, Name, ChatWithMessages, ChatStreamlyWithSender, Encode,
Rerank, ListModels, Balance, CheckConnection.
- Pattern parity with the merged moonshot (#14433), volcengine (#14460),
minimax (#14478), vllm (#14532), xai (#14550), and lm-studio (#14586)
PRs.
Closes#14604
## Summary
- Add MiniMax provider GroupId query parameter support in `LiteLLMBase`
- Extract `group_id` from key configuration in `__init__`
- Append `GroupId` as query parameter to `api_base` in
`_construct_complete_args`
## Why this change is needed
MiniMax provides an OpenAI-compatible API endpoint
(`/v1/chat/completions`), but `GroupId` is a MiniMax-specific account
identifier required for billing and rate limiting - it is not part of
the OpenAI standard.
Looking at LiteLLM's `MinimaxChatConfig`:
- `get_complete_url()` only constructs the base URL (e.g.,
`https://api.minimaxi.com/v1/chat/completions`)
- LiteLLM does **not** automatically inject `GroupId` into requests
- This must be handled by the caller (ragflow's chat_model.py)
The implementation appends `GroupId` as a query parameter to `api_base`:
```python
api_base = completion_args.get("api_base", self.base_url)
separator = "&" if "?" in api_base else "?"
completion_args["api_base"] = f"{api_base}{separator}GroupId={self.group_id}"
```
This matches MiniMax's official API format (as documented by
LlamaFactory):
```bash
curl --location 'https://api.minimaxi.chat/v1/text/chatcompletion?GroupId=你的GroupId' \
--header 'Authorization: Bearer 你的API_Key'
```
## Test plan
- [ ] Verify MiniMax API calls work with GroupId query parameter
- [ ] Verify backward compatibility for other providers
🤖 Generated with [Claude Code](https://claude.com/claude-code)
Co-authored-by: Claude Opus 4.7 <noreply@anthropic.com>
### What problem does this PR solve?
Bump to infinity v0.7.0-dev6
(uv lock --upgrade-package infinity-sdk)
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### What problem does this PR solve?
A and B, two API servers and a REDIS server.
If A and REDIS restart, B will hold the obsolete secret key and will
lead to error.
TODO:
app.config['SECRET_KEY'] and app.secret_key still hold obsolete secret
key.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
---------
Signed-off-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
support non-stream runtime agent completion
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
### What problem does this PR solve?
implement `lm-studio` provider
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
- [x] Refactoring
Fixes#14562
## Problem
LLMs like DeepSeek V4 Flash and Qwen3-MAX return \\( and \\[
(double backslash) in LaTeX output. The preprocessLaTeX() function
only handled single backslash delimiters, so equations showed as raw
text.
HTML entities like < and > were also not decoded.
## Solution
Added normalization step before existing delimiter conversion:
- \\( → \( and \\[ → \[
- < → < and > → > and & → &
---------
Co-authored-by: Vivek <viveksantoshkumardubey@email.com>
### What problem does this PR solve?
add file convert backward compatibility
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
This PR addresses three related GraphRAG reliability issues that
together allow long-running GraphRAG tasks (10+ hours of LLM extraction)
to be resumed after a crash or pause without re-doing completed work. It
builds on #14096 (per-doc subgraph cache) and extends the same idea to
the resolution and community-detection phases.
Fixes#14236.
## 1. Fix concurrent merge crash
Long GraphRAG runs would crash near the end of entity resolution with:
```
RuntimeError: dictionary keys changed during iteration
```
in `Extractor._merge_graph_nodes`. Two changes:
- `rag/graphrag/general/extractor.py`: snapshot `graph.neighbors(node1)`
via `list(...)` before iterating, so concurrent `add_edge` /
`remove_node` mutations on the shared `nx.Graph` cannot invalidate the
iterator. Also tracks each redirected neighbour in `node0_neighbors` so
a later merged node sharing the same external neighbour takes the
edge-merge branch instead of overwriting via `add_edge`.
- `rag/graphrag/entity_resolution.py`: serialize the merge step with a
dedicated `asyncio.Semaphore(1)`. `nx.Graph` is not thread-safe and
concurrent merges on overlapping neighbourhoods can produce incorrect
results even with the snapshot fix.
## 2. Don't wipe partial graph on pause
Previously the pause / cancel UI path called
`settings.docStoreConn.delete({"knowledge_graph_kwd": [...]}, ...)`,
destroying every subgraph, entity, relation, and graph row.
Re-triggering then started GraphRAG from scratch even though #14096 had
already added `load_subgraph_from_store`.
After main was merged in (which deleted `api/apps/kb_app.py` per
#14394), the pause path now lives on the new REST surface `DELETE
/v1/datasets/<id>/<index_type>`:
- `api/apps/services/dataset_api_service.py`: `delete_index` accepts a
`wipe: bool = True` parameter. When `False` the doc-store rows and
GraphRAG phase markers are left intact and only the running task is
cancelled. Default preserves historical behaviour.
- `api/apps/restful_apis/dataset_api.py`: parses `?wipe=false|0|no|off`
from the query string and forwards it.
- `web/src/utils/api.ts` + `web/src/services/knowledge-service.ts`:
`unbindPipelineTask` appends `?wipe=false` when explicitly false.
- The GraphRAG pause action in
`web/src/pages/dataset/dataset/generate-button/hook.ts` passes `wipe:
false` for `KnowledgeGraph`; raptor is unchanged.
**UX impact:** the pause icon next to a running GraphRAG task no longer
wipes graph data. The only path that still wipes is the explicit Delete
action in `GenerateLogButton` (trash icon behind a confirmation modal).
## 3. Phase-completion markers (`rag/graphrag/phase_markers.py`)
A small Redis-backed marker layer at
`graphrag:phase:{kb_id}:{resolution_done|community_done}` (7-day TTL).
`run_graphrag_for_kb` consults the markers on entry and skips phases
that already completed in a prior run. Markers are cleared automatically
when:
- new docs are merged into the graph (which invalidates prior resolution
and community results),
- `delete_index` wipes the graph, or
- `delete_knowledge_graph` is called.
Redis failures never block a run -- markers are an optimization, not a
gate.
## 4. Idempotent community detection
`extract_community` previously did `delete-then-insert` on
`community_report` rows; a crash mid-insert left the dataset with no
reports. Now report IDs are derived deterministically from `(kb_id,
community.title)`, the existing report IDs are snapshotted before
insert, new rows are written, then only stale rows are pruned. A failure
at any step leaves either the prior or the new report set intact --
never a partial mix.
## 5. Tunable doc-store insert pipeline
The GraphRAG insert loop in `rag/graphrag/utils.py` and the
`community_report` insert in `rag/graphrag/general/index.py` were both
hardcoded to `es_bulk_size = 4` and ran strictly sequentially. On a real
KB this meant 1077 chunks took ~21 minutes for a 100-chunk slice -- pure
round-trip overhead.
- New `insert_chunks_bounded()` helper in `rag/graphrag/utils.py`
batches inserts via a bounded `asyncio.Semaphore`. Same retry / timeout
semantics as the prior loop.
- Defaults: 64 docs per batch, 4 batches in flight (matches the regular
ingest pipeline in `document_service.py`). Tunable per-deployment via
`GRAPHRAG_INSERT_BULK_SIZE` and `GRAPHRAG_INSERT_CONCURRENCY`.
- Both `set_graph` and `extract_community` now use the helper.
This dropped the same 1077-chunk insert from minutes to seconds in local
testing without measurable extra pressure on Infinity (total in-flight
docs ≤ `BULK_SIZE × CONCURRENCY` = 256 by default).
## Tests
- `test/unit_test/rag/graphrag/test_merge_graph_nodes.py` (3 tests):
dense neighbourhood merge, neighbour-snapshot regression, concurrent
serialized merges.
- `test/unit_test/rag/graphrag/test_phase_markers.py` (4 tests): set/has
round-trip, kb-scoped clear, no-op on empty input, graceful Redis
failure.
-
`test/testcases/test_web_api/test_dataset_management/test_dataset_sdk_routes_unit.py`:
new `test_delete_index_wipe_flag_unit` covers `wipe=false` for both
GraphRAG and raptor on the new REST route, and confirms the default
still wipes and clears phase markers.
## Compatibility
- Backward compatible: tasks queued before this change behave
identically (default `wipe=true`, no markers expected).
- No schema/migration changes; all new state lives in Redis.
- New optional REST query param `wipe` on `DELETE
/v1/datasets/<id>/<index_type>`.
- New optional env vars `GRAPHRAG_INSERT_BULK_SIZE` and
`GRAPHRAG_INSERT_CONCURRENCY`; defaults preserve safe behaviour.
## Example of resume
Screenshot below shows a test resuming knowledge graph generation after
applying the concurrency fix and re-deploying.
<img width="521" height="677" alt="image"
src="https://github.com/user-attachments/assets/9ef0d405-cbb3-420d-a1a1-e51f3e7e9b7a"
/>
### Type of change
- [X] Bug Fix (non-breaking change which fixes an issue)
- [ ] New Feature (non-breaking change which adds functionality)
- [ ] Documentation Update
- [ ] Refactoring
- [ ] Performance Improvement
- [ ] Other (please describe):
### What problem does this PR solve?
This PR fixes a bug where `layout_recognize="<name>@OpenDataLoader"` was
misrouted and then failed during parsing in the naive parser path. It
now routes correctly to OpenDataLoader and avoids passing unsupported
arguments that caused runtime errors. fixes#14572
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
## Summary
This fixes a missing authorization check in the beta API document
download endpoint:
- **CWE:** CWE-862 (Missing Authorization)
- **Severity:** Medium
- **Affected route/file:** `GET /api/v1/documents/<document_id>` in
`api/apps/sdk/doc.py`
- **Data flow:** the route reads a bearer beta API token, resolves the
token with `APIToken.query(beta=token)`, accepts `document_id` directly
from the URL, loads the document with
`DocumentService.query(id=document_id)`, and then fetches the backing
object through `File2DocumentService.get_storage_address()` /
`settings.STORAGE_IMPL.get()`.
Before this change, that flow verified that the API token was valid, but
it did not verify that the token's tenant owned the document's knowledge
base. A caller with any valid beta API token and a known document ID
could therefore reach storage for a document belonging to another
tenant.
## Fix
The endpoint now takes the tenant ID from the resolved API token and
checks the document's knowledge base with:
```python
KnowledgebaseService.query(id=doc[0].kb_id, tenant_id=tenant_id)
```
If the knowledge base is not owned by the token tenant, the request
returns an access error before any storage lookup occurs. This mirrors
the tenant-scoped ownership checks used by the dataset-scoped document
download path and keeps the patch small.
## Tests
Added unit coverage for `download_doc()` to assert that:
- the beta token tenant ID is used in the knowledge-base ownership
lookup;
- cross-tenant access returns `You do not have access to this
document.`;
- storage resolution is not called before tenant authorization succeeds;
- the existing same-tenant empty-file and successful-download paths
still run after the authorization gate passes.
I also verified the final patch is limited to `api/apps/sdk/doc.py` and
the related document SDK route unit test. A local `pytest` invocation
could not complete in this checkout because the shared test fixture
attempts to log in to a RAGFlow server at `127.0.0.1:9380`, which was
not running in the local environment.
## Security analysis
This is exploitable when an attacker has a valid beta API token for
their own tenant and obtains or guesses a document ID from another
tenant. The token alone should not grant access to other tenants' files,
but the direct document route previously authorized only the token
itself and not the requested resource. The new tenant-scoped
knowledge-base check binds the requested document back to the token
tenant before storage is accessed, preventing cross-tenant document
downloads through this endpoint.
Before submitting, we attempted to disprove this by checking whether
existing dataset-scoped routes, token validation, or framework
protections already enforced ownership. They do not apply to this direct
document-ID route: it bypassed the dataset path parameter and used only
`DocumentService.query(id=document_id)` before reading storage.
cc @lewiswigmore
### What problem does this PR solve?
### Type of change
- [v] Bug Fix (non-breaking change which fixes an issue)
Co-authored-by: wiratama <dafa.wiratama@bankraya.co.id>
### What problem does this PR solve?
Fix#14340
## Problem Description
When using an **Agentic Agent** (not Workflow) with one or more
Retrieval tools (e.g., Dataset Retrieval + Memory Retrieval), the agent
silently returns an empty response (`agent_response: ""`) after hanging
for several minutes. The server logs show:
```
AttributeError: 'ChatCompletionMessageToolCall' object has no attribute 'index'
```
This error propagates as a `GENERIC_ERROR`, causing the canvas to return
an empty response. The subsequent Memory save task then receives the
empty `agent_response` and logs:
```
Document for referred_document_id XXXX not found
```
## Reproduction Steps
1. Set `DOC_ENGINE=infinity` (or `elasticsearch` — the engine itself is
not the root cause).
2. Create a blank **Agentic Agent** (not a Workflow).
3. Add **two Retrieval tools** to the Agent node:
- `Retrieval_DS` → Dataset (Knowledge Base)
- `Retrieval_Mem` → Memory component
4. Add a **Message** node with **Save to Memory** enabled.
5. Launch the agent and send any message (e.g., "hola").
6. The agent hangs and returns an empty response.
## Root Cause Analysis
The crash occurs in `_append_history` and `_append_history_batch` inside
`rag/llm/chat_model.py`. These methods directly access `.index` on tool
call objects:
```python
# _append_history_batch
{
"index": tc.index, # <-- crashes here
...
}
```
However, **non-streaming** LLM responses (`stream=False`) return
`ChatCompletionMessageToolCall` objects, which **do not have an `index`
field** according to the OpenAI API specification. The `index` field
only exists on `ChoiceDeltaToolCall` objects returned in **streaming**
responses (`stream=True`).
When the agentic agent triggers an internal `full_question` call (used
to compress multi-turn conversation history), the request is incorrectly
routed through `async_chat_with_tools` because `is_tools=True` is set at
the `LLMBundle` level. If the LLM decides to emit `tool_calls` during
this auxiliary request, the code enters the non-streaming tool loop and
crashes when trying to append history.
## Fix
Replaced all direct `.index` accesses with `getattr(..., "index", None)`
for safe, backward-compatible access:
| Method | File | Line | Change |
|--------|------|------|--------|
| `_append_history` | `rag/llm/chat_model.py` | ~L304 |
`tool_call.index` → `getattr(tool_call, "index", None)` |
| `_append_history_batch` | `rag/llm/chat_model.py` | ~L332 | `tc.index`
→ `getattr(tc, "index", None)` |
| `_append_history` | `rag/llm/chat_model.py` | ~L1467 |
`tool_call.index` → `getattr(tool_call, "index", None)` |
| `_append_history_batch` | `rag/llm/chat_model.py` | ~L1496 |
`tc.index` → `getattr(tc, "index", None)` |
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
Signed-off-by: noob <yixiao121314@outlook.com>
## Summary
- normalize string items for list-valued metadata filters in
`meta_filter`
- fix `in` / `not in` case asymmetry when document metadata is
lowercased but filter list values are not
- add regression tests that cover the original issue scenario using
uppercase list values
## Validation
- `PYTHONPATH=external/ragflow pytest
external/ragflow/test/unit_test/common/test_metadata_filter_operators.py
-q`
## Notes
- I commented on #14389 before opening this PR to claim the issue.
- The new tests use `value=["F2", "F11"]` so they fail on the old
implementation and pass with this fix.
- This also benefits other non-comparison operators that flow through
the same normalization path.
Co-authored-by: copizza <copizza@users.noreply.github.com>
Co-authored-by: Wang Qi <wangq8@outlook.com>
### What problem does this PR solve?
add legacy agent completion API compatibility
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
### What problem does this PR solve?
This PR fixes missing authorization checks in the Memory API.
Previously, several authenticated endpoints accepted caller-supplied
`tenant_id`, `owner_ids`, or `memory_id` values and used them directly
to list, read, update, delete, or search Memory data.
That could allow an authenticated user to access or mutate another
tenant's Memory records if they knew a tenant ID or memory ID. The fix
centralizes Memory access checks and applies them consistently across
Memory and Memory-message operations.
The change:
- Adds helper logic to parse list filters and compute tenant IDs
accessible to `current_user`.
- Requires direct `memory_id` operations to pass Memory access checks
before reading, updating, deleting, or changing message state.
- Filters list/search/recent-message requests to accessible memories
only.
- Applies Memory visibility filtering before count and pagination in
`MemoryService.get_by_filter`.
- Accepts `owner_ids` in the Memory list route, matching the frontend
owner filter while still intersecting values with the caller's
accessible tenants.
-
### Related issues
Closes#14534
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
Co-authored-by: jony376 <jony376@gmail.com>
### What problem does this PR solve?
add IMAP deleted document sync
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### What problem does this PR solve?
Incremental DingTalk AI Table (Notable) sync did not reconcile rows
removed on the remote side with documents already in the knowledge base.
This follows the coordinated datasource work in #14362 (“sync deleted
files”).
This PR adds a **full slim snapshot**
(`retrieve_all_slim_docs_perm_sync`) that lists **current record IDs for
all sheets** without building document blobs, using the same logical
document IDs as full ingest
(`dingtalk_ai_table:{table_id}:{sheet_id}:{record_id}`). When
**`sync_deleted_files`** is enabled on incremental runs,
`DingTalkAITable._generate` returns **`(document_generator,
file_list)`** so **`SyncBase`** can run
**`cleanup_stale_documents_for_task`** and remove KB rows that no longer
exist remotely.
Design notes:
- **`_document_id`** centralizes the ID string so slim snapshots and
**`_convert_record_to_document`** stay aligned with
**`hash128(doc.id)`** semantics used during ingestion/cleanup.
- **`end_ts`** is captured before building **`file_list`**, then
**`poll_source`** uses the same upper bound (consistent with other
Dropbox-style connectors).
- **`batch_size`** from connector config is coerced to a positive
**`int`** before constructing the connector.
- Slim snapshot failures are caught in **`_generate`**; **`file_list`**
is set to **`None`** so cleanup is skipped rather than running on
partial/error state.
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### Files changed (summary)
| Area | Change |
|------|--------|
| `common/data_source/dingtalk_ai_table_connector.py` |
`SlimConnectorWithPermSync`, `retrieve_all_slim_docs_perm_sync`,
`_document_id` shared with document conversion |
| `rag/svr/sync_data_source.py` | `DingTalkAITable._generate`: slim
snapshot + tuple return; `batch_size` validation; shared `end_ts` with
`poll_source` |
| `web/src/pages/user-setting/data-source/constant/index.tsx` |
`syncDeletedFiles` for DingTalk AI Table in
`DataSourceFeatureVisibilityMap` |
Closes / relates to: #14362
### What problem does this PR solve?
This fixes a MinerU parsing failure where output JSON was not found in
nested v0.24.0 layouts, and also fixes a `content_names` NameError in
`_read_output()`. As a result, successful MinerU API runs no longer end
with false “MinerU not found” parsing failures.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
Concurrent CREATE TABLE / CREATE INDEX / DROP TABLE on the same Infinity
instance can race on the catalog counter (e.g. db|1|next_table_id) and
fail with error 9003 "Resource busy" instead of waiting on a lock. Two
users creating a knowledge base at the same instant, or any deployment
with multiple backend workers behind one Infinity, can hit it.
Wrap the metadata paths in create_idx, create_doc_meta_idx, and
delete_idx with exponential backoff + jitter (5 attempts, 50ms base).
The wrapped operations already use ConflictType.Ignore, so retrying is
idempotent — worst case the second attempt is a no-op against an
already-created table. Tunable via INFINITY_META_RETRY_MAX /
INFINITY_META_RETRY_BASE_DELAY_MS.
Repro: stress 30 concurrent POST /api/v1/datasets against a 4-worker
backend → ~50% of requests fail without the patch (Resource busy from
the second worker that hits the counter), 100% succeed with it. At 100
concurrent requests, all 100 succeed in ~1.2s; the retry budget never
exhausted in our tests.
Scope is limited to metadata paths only — data-path operations (INSERT
chunks, SELECT for retrieval) go through per-table code paths and don't
share the contended counter.
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
---------
Co-authored-by: yoan sapienza <Yoan Sapienza yoan.sapienza@orange.fr Yoan Sapienza zappy@macbookpro.home>
Closes#14552
### What problem does this PR solve?
Add a Go driver for xAI (Grok models).
The config file conf/models/xai.json has been in the repo since the
early Go provider work, but internal/entity/models/factory.go had no
case for "xai". So any xAI request fell through to the dummy driver
and never reached the API. This PR adds the missing driver and wires it
up.
### What this PR includes
- New file internal/entity/models/xai.go with an XAIModel that
implements the ModelDriver interface.
- factory.go: route the "xai" provider name to NewXAIModel.
### How the driver works
- xAI exposes an OpenAI-compatible API at https://api.x.ai/v1.
- ChatWithMessages and ChatStreamlyWithSender post to /chat/completions
in the same shape the moonshot and deepseek drivers use.
- ListModels and CheckConnection call /models to confirm the API key
works and to list available model ids.
- reasoning_content is passed through for grok-3-mini and other xAI
reasoning models, both in the non-stream and stream paths.
- Encode, Rerank, and Balance are not part of the public xAI API at the
moment, so they return a clear "not implemented" or "no such method"
error.
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
### How was this tested?
- go build ./internal/entity/models/... in a clean go 1.25 image (the
go.mod minimum) returns exit 0 with no errors.
- Method set of XAIModel matches the ModelDriver interface: NewInstance,
Name, ChatWithMessages, ChatStreamlyWithSender, Encode, Rerank,
ListModels, Balance, CheckConnection.
- Pattern parity with the merged moonshot (#14433), volcengine (#14460),
minimax (#14478), and vllm (#14532) PRs.
---------
Co-authored-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
implement `Ollama` provider
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
- [x] Refactoring
---------
Co-authored-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
Use GetChatModel, remove duplicate functions in model_service.go
### Type of change
- [x] Refactoring
Co-authored-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
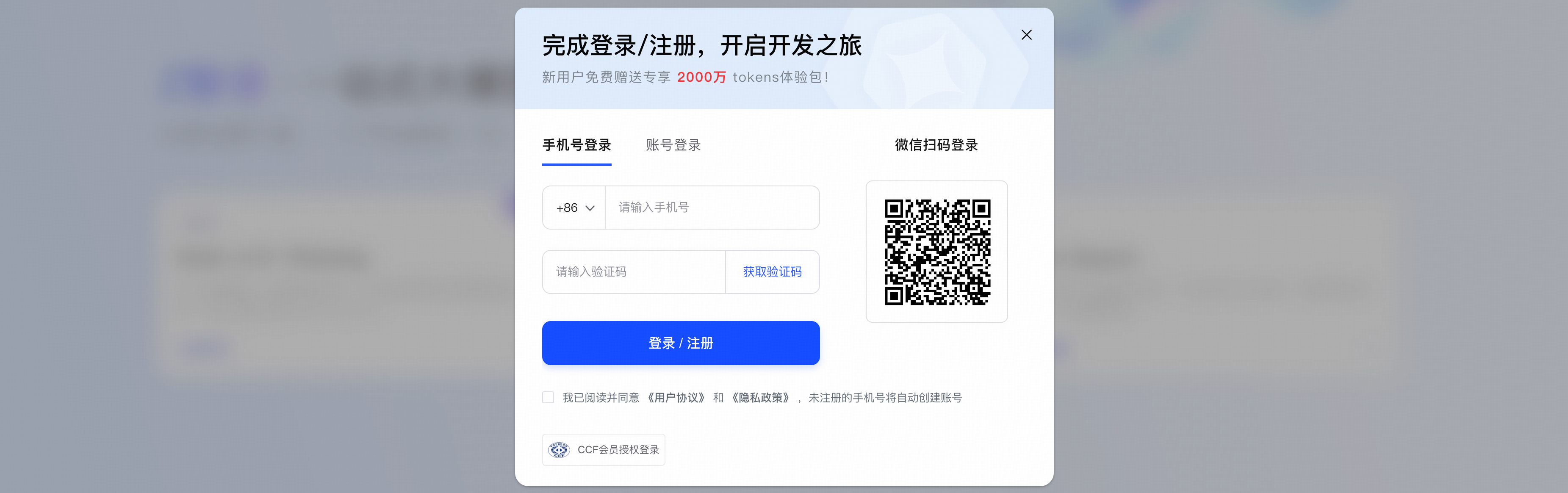
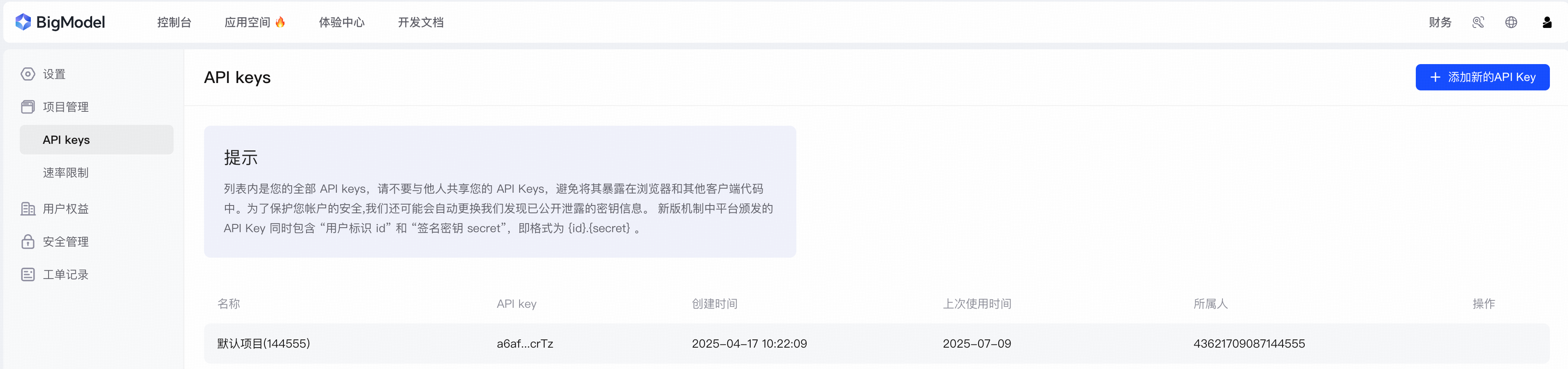
```
RAGFlow(user)> chat with 'glm-4.6v-flash@test@zhipu-ai' message 'What are the pics talk about?' image 'https://cdn.bigmodel.cn/static/logo/register.png' 'https://cdn.bigmodel.cn/static/logo/api-key.png'
Answer: The first picture shows a login/register modal with options for phone number login, account login, and WeChat QR code login, along with a prompt for new users to get a 20 million tokens experience package. The second picture displays the API keys management page of a platform, including a warning about API key security and a table listing existing API keys with details like creation time and usage history.
Time: 31.600545
RAGFlow(user)> chat with 'glm-4.6v-flash@test@zhipu-ai' message 'What are the video talk about?' video 'https://cdn.bigmodel.cn/agent-demos/lark/113123.mov'
Answer: Based on the sequence of frames provided, the video is a demonstration of a web search and navigation process.
1. The video starts with a blank Google search page.
2. The user types "智谱" (which is the Chinese name for the company Zhipu AI) into the search box.
3. The search is initiated and the page shows "About 0 results".
4. The search results load, showing information about Zhipu AI, including its website.
5. The user clicks on the main website link (www.zhipuai.cn).
6. The video ends by showing the homepage of Zhipu AI's website, titled "Z.ai GLM Large Model Open Platform".
In summary, the video is about searching for the company "智谱" (Zhipu AI) on Google and then navigating to its official website.
Time: 76.582520
```
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
Signed-off-by: Jin Hai <haijin.chn@gmail.com>
### What problem does this PR solve?
Currently, RAGFlow's Search and Chat interfaces display only raw
vectorized text chunks during retrieval, without contextual information
about their source documents. Users cannot see document titles, page
numbers, upload dates, or custom metadata fields that would help them
understand and trust the retrieved results.
This PR introduces an **optional metadata display feature** that
enriches retrieved chunks with document-level metadata in both the
Search tab and Chatbot interface.
**Key improvements:**
- **Search results**: Display document metadata as styled badges beneath
chunk snippets
- **Chat citations**: Show metadata in citation popovers and reference
lists for better source context
- **LLM context**: Metadata is injected into the LLM prompt to enable
more accurate, citation-aware responses
- **External API support**: Applications using RAGFlow's SDK retrieval
endpoints (`/v1/retrieval`, `/v1/searchbots/retrieval_test`) can opt-in
via request parameters
- **User control**: Multi-select dropdown UI allows users to choose
which metadata fields to display
**Implementation approach:**
- ✅ Reuses existing `DocMetadataService` infrastructure (no new database
tables or indices)
- ✅ Settings stored in existing JSON configuration fields
(`search_config.reference_metadata`, `prompt_config.reference_metadata`)
- ✅ No database migrations required
- ✅ Disabled by default (fully opt-in and backward-compatible)
- ✅ Dynamic metadata field selection populated from actual document
metadata keys
- ✅ Fixed critical bug where Python's builtin `set()` was shadowed by a
route handler function
**Modified endpoints (all backward-compatible):**
- `POST /v1/retrieval` (Public SDK)
- `POST /v1/searchbots/retrieval_test` (Searchbots)
- `POST /v1/chunk/retrieval_test` (UI/Internal)
- Chat completions endpoints (via `extra_body.reference_metadata` or
`prompt_config`)
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
###Images
-
<img width="879" height="1275" alt="image"
src="https://github.com/user-attachments/assets/95b2d731-31ae-45a1-b081-bf5893f52aeb"
/>
<br><br>
<br><br>
<img width="1532" height="362" alt="image"
src="https://github.com/user-attachments/assets/9cebc65b-b7a7-459f-b25e-3b13fa9b638e"
/>
<br><br>
<br><br>
<img width="2586" height="1320" alt="image"
src="https://github.com/user-attachments/assets/2153d493-d899-461f-a7a9-041391e07776"
/>
---------
Co-authored-by: Cursor Agent <cursoragent@cursor.com>
Co-authored-by: Attili-sys <Attili-sys@users.noreply.github.com>
Co-authored-by: Ahmad Intisar <ahmadintisar@Ahmads-MacBook-M4-Pro.local>
### What problem does this PR solve?
remove delete_documents uuid validation
### Type of change
- [x] Bug Fix (non-breaking change which fixes an issue)
### What problem does this PR solve?
Partially addresses #14362.
This PR enables syncing deleted files for RSS data sources.
Previously, RSS incremental sync only returned feed entries whose
timestamps were inside the poll window. If an entry was removed from the
RSS feed, RAGFlow had no full current RSS snapshot to pass into the
shared stale-document cleanup path, so the deleted remote entry could
remain in the knowledge base.
This PR:
- adds `retrieve_all_slim_docs_perm_sync()` to `RSSConnector`
- reuses the same `rss:<md5(stable_key)>` document ID derivation used by
normal RSS ingest
- returns `(document_generator, file_list)` for incremental RSS sync
when `sync_deleted_files` is enabled
- captures the poll end timestamp before snapshot/poll so cleanup does
not race against the same sync window
- adds start/end logs around RSS slim snapshot collection
- exposes the deleted-file sync toggle for RSS in the data source UI
Per maintainer request on related datasource PRs, this PR contains no
test-case changes. Local verification was run with an external script.
Validation:
- `uv run ruff check common/data_source/rss_connector.py
rag/svr/sync_data_source.py`
- `uv run pytest test/unit_test/rag/test_sync_data_source.py -q`
- `./node_modules/.bin/eslint
src/pages/user-setting/data-source/constant/index.tsx`
- `git diff --check`
- `uv run python /tmp/verify_rss_deleted_sync.py --repo
/root/74/ragflow`
### Type of change
- [x] New Feature (non-breaking change which adds functionality)
{kind=link}
{kind=link}